Week2-2
A New Week!

We aren’t computer scientists and that’s okay!
We make lots of mistakes. Mistakes are funny. You can laugh with us.
Let’s go, Simba, Pumbaa, and Timon!
1 Comparing values
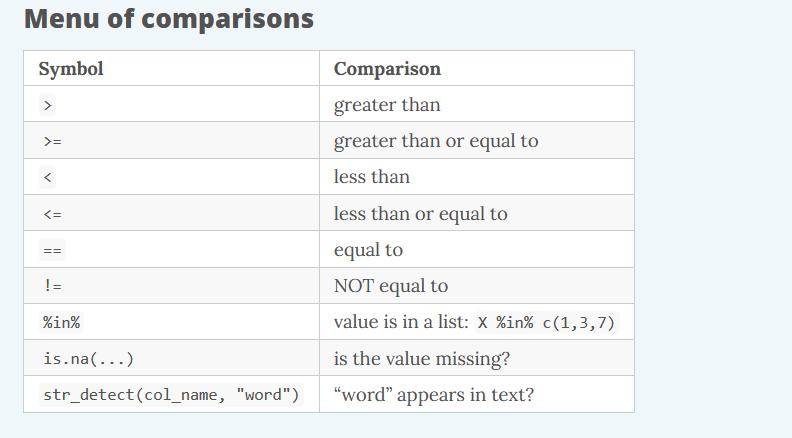
We use a variety of comparisions when processing data. For example, we only want concentrations above a certain level, or months in summer, or sites that have missing observations.
We the following relational operators to find the data we want.
Exercise 1
Try comparing some things to see if you get what you’d expect.
4 != 5
4 == 4
4 < 3
4 > c(1, 3, 5)
5 == c(1, 3, 5)
5 %in% c(1, 3, 5)
2 %in% c(1, 3, 5)
2 == NA
Missing values (NA) are regarded as non-comparable even to themselves, so comparisons involving them will always result in NA
2 Pipe operator %>%
The pipe operator passes the result of one step as input for the next step. We use it to chain functions together and make our scripts more streamlined.
Keyboard shortcut: Ctrl+Shift+M
Here are 2 ways the %>% is helpful:
- It eliminates the need for nested parentheses.
Say you wanted to take the sum of 3 numbers and then take the log and then round the final result.
The code doesn’t look much like the words we used to describe it. Let’s pipe it so we can read the code from left to right.
- We can combine many processing steps into one cohesive chunk.
Here are some of the functions we’ve applied to the airquality data so far:
library(dplyr)
head(airquality)
airquality_new <- select(airquality, Ozone, Month, Day)
airquality_new <- arrange(airquality_new, desc(Ozone))
airquality_new <- mutate(airquality_new, city = "New York")We can use the %>% operator to pipe or chain them together.
3 Manipulate data

dplyr is the hero for most analysis tasks.
With these six functions you can accomplish just about anything you want with your data.
select() : select individual columns to keep or drop
arrange(): sort a table top-to-bottom based on the values of a column
mutate(): add new columns or dupate exsiting columns
filter(): keep only a subset of rows depending on the values of a column
summarize(): calculate a single summary for an entire table
group_by(): sort data into groups based on teh vales of a column
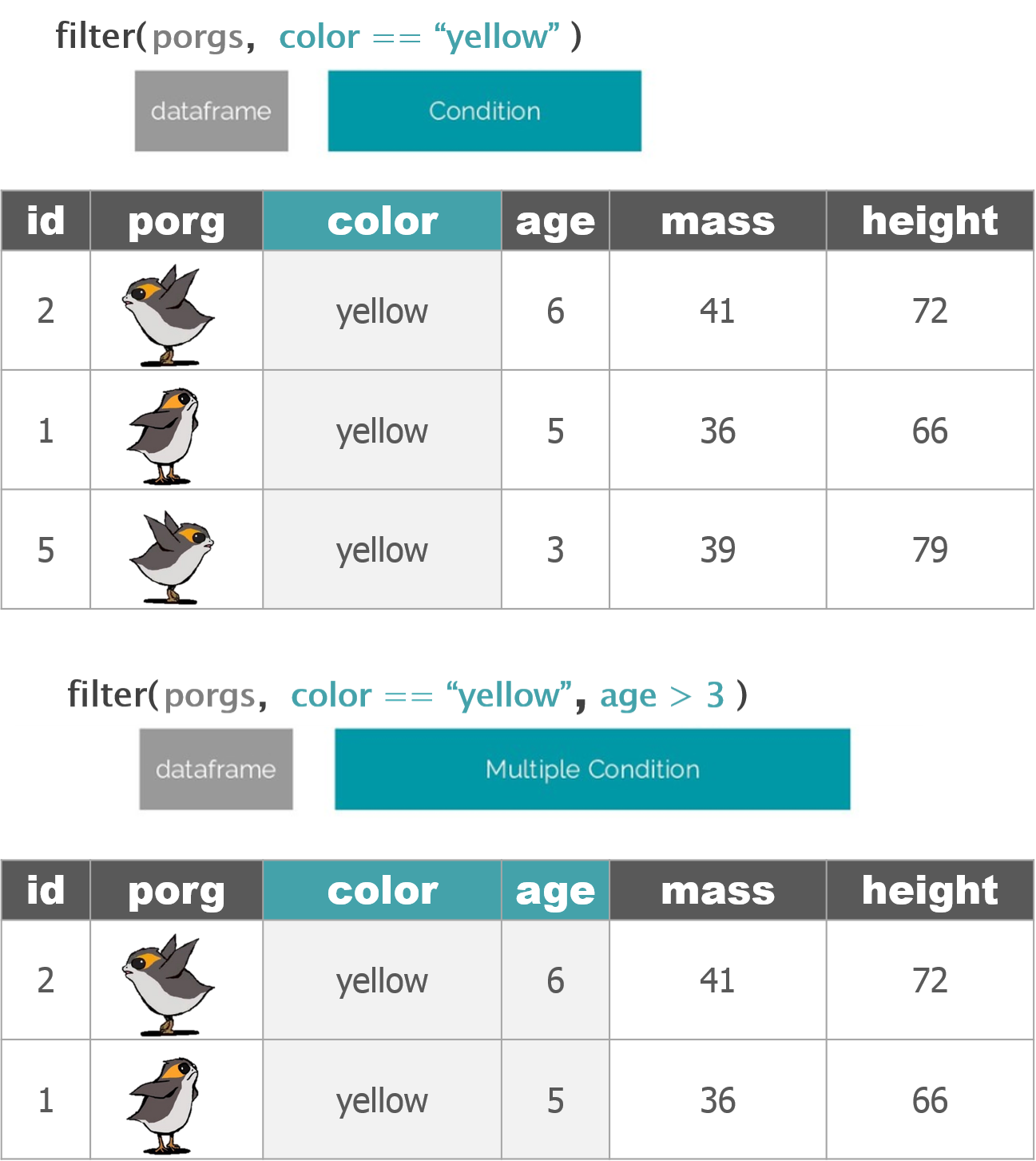
3.1 filter()
The filter() function creates a subset of the data based on the value of one or more columns. This function takes 2 arguments:
- a dataframe
- a conditional expression that evaluates to TRUE or FALSE
3.1.1 Select rows
Let’s take a look at ozone concentration in August
3.1.2 Drop rows
Let’s look at the ozone concentration in months after May. We’re going to filter our data to keep only the months that are NOT equal to 5.
3.1.3 Multiple conditions
We can add multiple comparisons to further restrict the data. Only the records that pass the conditions of all the comparisons will be selected.
The code below filters ozone higher than 70 ppb AND in August.
We can use logical operators to string together multiple different conditions.
& (logical AND)
| (logical OR)
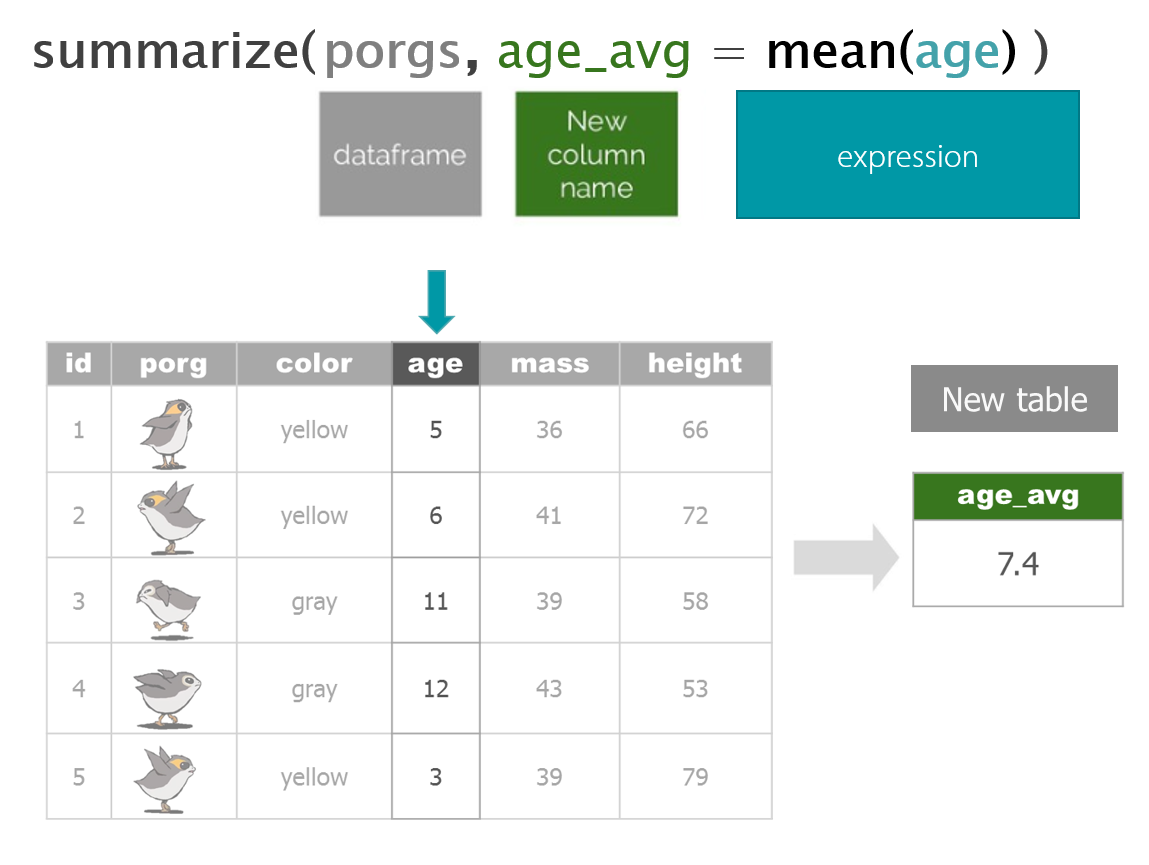
3.2 summarize()
The summarize() or summerise() function reduces a data frame to a summary of just one vector or value.
Many times, these summaries are calculated by grouping observations.
3.3 group_by()
The group_by() function is used to group data.

airquality_group <- group_by(airquality, Month) %>%
summarize(ozone_avg = mean(Ozone, na.rm = T))
airquality_groupExercise 2
import ozone data from ozone_samples_demo.csv
find the max ozone in each month for the SiteNum of 7554
4 Recap
relational operators
pipe operator
filter()
summarize()
group_by()